This is probably not the first blog you have read on the Facebook / WhatsApp / Instagram (for the sake of verbiage, I’ll just refer to it as ‘Facebook’ from here on) outage, and it probably won’t be the last, but here are my observations from the Janet network.
Unlike many services used on the Internet which may use a hybrid of their own servers and the larger ‘cloud’ or content delivery providers like AWS, Cloudflare, LimeLight, etc., Facebook delivers all (or at least almost all) of its content from its own Content Delivery Network (CDN). Facebook’s CDN has a global footprint, is extremely large, and highly automated. We have two private interconnections to the Facebook CDN at different locations in London’s Docklands, and also peer over Internet exchanges.
Just after 16:30 on 4th October, traffic from Facebook to Janet (and the rest of the world) vanished.
This sort of failure is unusual. When large cloud service providers break, it’s usually a partial failure and we’ll get reports of something that’s broken for one of our members, but not for another, or that it’s broken on Janet but reachable from home (hopefully more often it is the other way around).
What was going on?
The first noticeable thing is that if you tried to lookup ‘www.facebook.com’ in the DNS, there was no answer. Digging (ahem) a bit more, the domain facebook.com is delegated to four nameservers, each with an IPv6 and an IPv4 address:
;; QUESTION SECTION:
;facebook.com. IN NS
;; AUTHORITY SECTION:
facebook.com. 172800 IN NS a.ns.facebook.com.
facebook.com. 172800 IN NS b.ns.facebook.com.
facebook.com. 172800 IN NS c.ns.facebook.com.
facebook.com. 172800 IN NS d.ns.facebook.com.
;; ADDITIONAL SECTION:
a.ns.facebook.com. 172800 IN A 129.134.30.12
a.ns.facebook.com. 172800 IN AAAA 2a03:2880:f0fc:c:face:b00c:0:35
b.ns.facebook.com. 172800 IN A 129.134.31.12
b.ns.facebook.com. 172800 IN AAAA 2a03:2880:f0fd:c:face:b00c:0:35
c.ns.facebook.com. 172800 IN A 185.89.218.12
c.ns.facebook.com. 172800 IN AAAA 2a03:2880:f1fc:c:face:b00c:0:35
d.ns.facebook.com. 172800 IN A 185.89.219.12
d.ns.facebook.com. 172800 IN AAAA 2a03:2880:f1fd:c:face:b00c:0:35OK, having four NS records with the addresses covered by two IPv4 prefixes and one IPv6 prefix may not be how I’d design a large service, but Facebook has that global CDN, remember, so there will be hundreds or thousands of different servers around the globe all listening on those addresses, so why wasn’t I getting a response? At this point, it probably pays to look at the routes to those servers.
rhe@myrouter> show route 129.134.30.12 table inet.0
inet.0: 854670 destinations, 2128859 routes (854664 active, 3 holddown, 3 hidden)
+ = Active Route, - = Last Active, * = Both
129.134.0.0/17 *[BGP/170] 7w4d 16:50:13, MED 300, localpref 100, from aa.bb.cc.dd
AS path: 32934 ?, validation-state: unverified
> to ee.ff.gg.hh via ae24.0
[BGP/170] 1w6d 16:52:01, MED 300, localpref 100, from ii.jj.kk.ll
AS path: 32934 ?, validation-state: unverified
> to mm.nn.oo.pp via ae28.0
[BGP/170] 3d 16:19:36, MED 305, localpref 100, from qq.rr.ss.tt
AS path: 32934 ?, validation-state: unverified
> to uu.vv.ww.xx via ae23.0We’ve got a route, that’s good news, though it covers both of the first two NS records and a traceroute dies at our last hop. What about the other two?
rhe@myrouter> show route 185.89.218.12 table inet.0
inet.0: 854652 destinations, 2128883 routes (854647 active, 2 holddown, 3 hidden)
+ = Active Route, - = Last Active, * = Both
0.0.0.0/0 *[BGP/170] 5w3d 06:26:31, MED 0, localpref 2, from aa.bb.cc.dd
AS path: (65533) I, validation-state: unverified
> to ee.ff.gg.hh via ae28.0
[BGP/170] 6w6d 21:31:30, MED 0, localpref 2, from ii.jj.kk.ll
AS path: (65533) I, validation-state: unverified
> to mm.nn.oo.pp via ae27.0Oh, that’s less good. Whilst we carry a full routing table, we don’t have a route to the other two NS records, it’s matching the default route (which will just head to one of our own routers that generates it). Something is definitely awry.
Unfortunately at this point it is apparent (from watching Twitter if nothing else) that this is a global outage and there’s not much we can do except sit and wait.
What else was going on? Of course, a lot of other websites these days use Facebook for authentication (“Log in with Facebook”), so as credentials timed out, sessions couldn’t be renewed. Open DNS resolver services, such as Cloudflare who operate 1.1.1.1, reported DNS query rates for Facebook services rising to about 30x the normal levels.
As I write this, it is 24 hours since the problem was solved and details have started to emerge. Facebook have issued a couple of blogs about the problem. Firstly a brief blog shortly after the event stating it was caused by a configuration change, then today a far more detailed blog. The latter is well worth reading.
A fundamental part of operating a CDN is knowing when a node is failing and withdrawing the routes that node is advertising to the Internet. That allows traffic to pick the next best route, which will hopefully be to a functioning node (this is called “anycast”). This time, the software believed all the nodes were broken and withdrew all of the routes. The problem was compounded by the management, measurement and diagnostic tools using the same infrastructure, so the operators were blind to what was going on.
The result was the following traffic pattern over our two private interconnections with Facebook on 4th October.
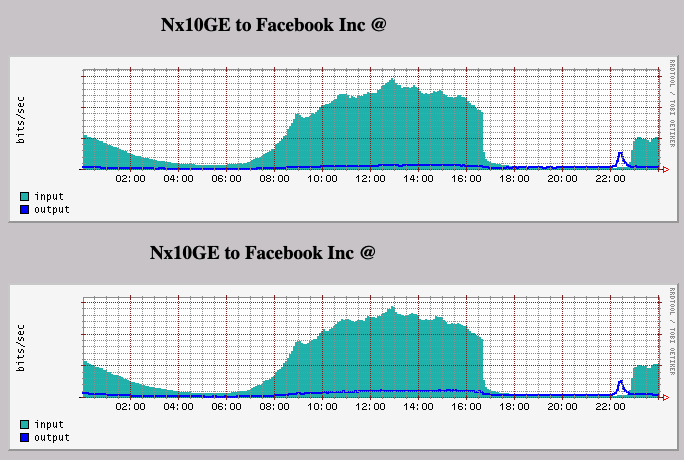
Just before Facebook started serving traffic again there is an interesting lump of traffic outbound towards them. I’ve no idea what this is — a backlog of photo and video updates to the three services?
What does it look like from our point of view at the moment?
Now that Facebook’s DNS resolvers are working, this is what I see when we look up www.facebook.com on a system on Janet:
;; QUESTION SECTION:
;www.facebook.com. IN ANY
;; ANSWER SECTION:
www.facebook.com. 3600 IN CNAME star-mini.c10r.facebook.com.
www.facebook.com is a CNAME (DNS alias) for ‘star-mini.c10r.facebook.com’. Which in turn resolves to:
;; QUESTION SECTION:
;star-mini.c10r.facebook.com. IN ANY
;; ANSWER SECTION:
star-mini.c10r.facebook.com. 60 IN AAAA 2a03:2880:f158:82:face:b00c:0:25de
star-mini.c10r.facebook.com. 60 IN A 157.240.221.35
This is fairly typical for the way a CDN operates, the DNS resolvers use CNAMEs to direct traffic to local instances of their CDN. ‘www.facebook.com’ appears to resolve to ‘star-mini.c10r.facebook.com’ wherever you are in the world, but the IP addresses for ‘star-mini.c10r.facebook.com’ vary depending where you are. This traffic localisation is dependent on the topology of the Facebook network and its interconnections with other service providers, so it is difficult for them to outsource to a third-party DNS host (there are DNS providers that will do it, but I imagine FB feels its own algorithms are better than the ones they might deploy).
If I look up the same address from my UK-based home broadband, it currently resolves to 157.240.240.35.
If you look at the ‘Local DNS’ tab of nslookup.io, you can see these different results from a few vantage points around the world.
Looking at the routing table in Janet, the nameservers now have more specific routes, so a.ns.facebook.com follows a /24 (/48 for IPv6) through one of our transit providers, whilst [bcd].ns.facebook.com use our direct peering, both for IPv4 and IPv6.
A lot of pundits are drawing a lot of conclusions about this outage. Many of them are blaming the BGP and DNS protocols for the outage, saying they’re understood by nobody, or that they are the Internet’s equivalent of sticky tape and string. Others note that if there was less centralisation, then failures would have a smaller impact. I’m wary of drawing too many conclusions, basically it was a highly automated system that did insufficient checks on some commands which had unforeseen consequences. This sort of thing has happened before, and it will happen again, and we need to do our best to learn from it. You can’t run something of the scale of Facebook without automation, and it’s as easy to automate a failure as it is to automate a new service.
However, if you know someone that works in network engineering at Facebook, buy them a beer next time you see them, they probably had a hec of a day yesterday.
As an aside, the amount of traffic we lost from what are interactive applications shows just how many people are now back on campus at UK Universities, so it may be time for me to do another blog as a retrospective of the last 19 months on Janet.